The Best Server CPUs part 2: the Intel "Nehalem" Xeon X5570
by Johan De Gelas on March 30, 2009 3:00 PM EST- Posted in
- IT Computing
Virtualization (ESX 3.5 Update 2/3)
More than 50% of the servers are bought to virtualize. Virtualization is thus the killer application and the most important benchmark available. VMware is by far the market leader with about 80% of the market. However, we encountered - once again - serious issues in getting ESX installed and running on the newest platform. ASUS told us we need the ESX Update 4, which we do not yet have in the labs. We are doing all we can to make sure that our long awaited hypervisor comparison will be online in April, so stay tuned. Since we have not been able to carry out our own virtualization benchmarking, we turn to VMware's VMmark.
VMware VMmark is a benchmark of consolidation. Several virtual machines performing different tasks are consolidated, creating a tile. A VMmark tile consists of:
- MS Exchange VM
- Java App VM
- Idle VM
- Apache web server VM
- MySQL database VM
- SAMBA fileserver VM
The first three run on a Windows 2003 guest OS and the last three on SUSE SLES 10.
Let us first see how many tiles (six VMs per tile) each server can support:
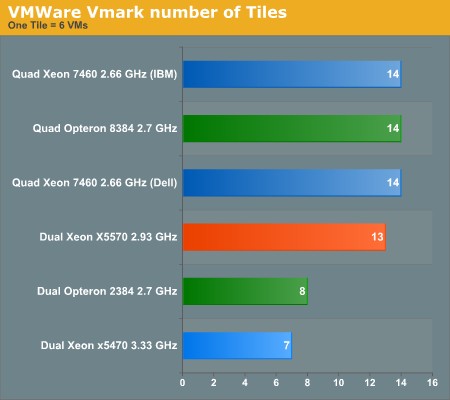
The newest Xeon is shattering records again: with 13 tiles (in 72GB) it can consolidate by far the most VMs in a dual socket server. It is already dangerously close to the quad socket servers with up to 128GB of RAM. It is important to note that once you use more than one DIMM per channel, the maximum DDR3 speed is 1066. Once you fill up all slots (three DIMMs per channel, nine DIMMs per CPU), the DDR3 memory is running at 800MHz. Intel's official validation results can be found here.
Nevertheless, the performance impact of lower DDR3 speeds is not large enough to offset the advantage of three DIMMs per channel: up to 18 DIMMs in a dual configuration is a record. So far, AMD's latest Opteron held the record with eight DIMMs per CPU, or a maximum of 16 per dual socket server. AMD' supports up to three DIMMs per channel at 800MHz. Once you use four DIMMs (eight per CPU) per channel, the clock speed falls back to 533MHz. That is also a reason, besides pure performance, why Intel can support 13 tiles or 78 light VMs per server: Intel used 72GB of DDR3 at 800MHz. AMD is stuck at eight tiles for the moment: the dual Opteron servers get 64GB (at 533MHz) at the most.
After a benchmark run, the workload metrics for each tile are computed and aggregated into a score for that tile. This aggregation is performed by first normalizing the different performance metrics such as MB/second and database commits/second with respect to a reference system. Then, a geometric mean of the normalized scores is computed as the final score for the tile. The resulting per-tile scores are then summed to create the final metric.
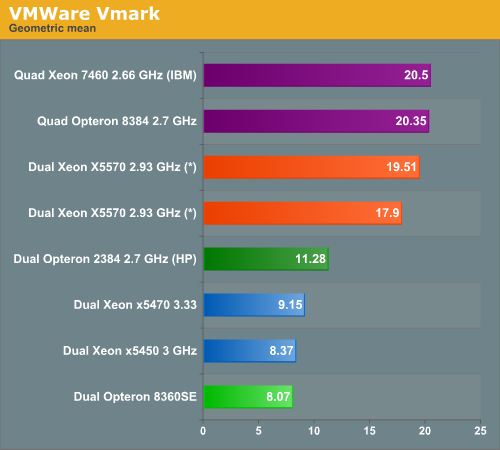
(*) preliminary benchmark data
World switch times from VM to hypervisor have been reduced to 40% of those of Clovertown (Xeon 53xx), and EPT is good for a 27% performance increase. Add a massive amount of memory bandwidth, and we understand why the Nehalem EP shines in this benchmark. The scores for the Xeon X5570 are however preliminary: we have seen scores range from 17.9 to 19.51, but always with 13 tiles. The ESX version was not an official version ("VMware ESX Build 140815") which will probably morph into ESX 3.5 Update 4. AMD's results might also get a bit better with ESX 3.5 Update 4, so take the results with a grain of salt, but they give a good first idea. There is little doubt that the newest Xeon is also the champion in virtualization.
Both AMD and Intel emphasize that you can "vmotion" across several generations. AMD demonstrated that it is possible to migrate from the hex-core Istanbul to the quad-core Barcelona, while Intel demonstrated vmotion between "Harpertown" and "Nehalem".

It will be interesting to see how far you can go with this in practice. In theory you can go from Woodcrest to Nehalem. It is funny to see that Intel (and AMD to a lesser degree) have to clean up the mess they made with the incredibly chaotic ISA SIMD extensions: from MMX to more SSE extensions then we care to remember.








44 Comments
View All Comments
snakeoil - Monday, March 30, 2009 - link
oops it seems that hypertreading is not scaling very well too bad for inteleva2000 - Tuesday, March 31, 2009 - link
Bloody awesome results for the new 55xx series. Can't wait to see some of the larger vBulletin forums online benefiting from these monsters :)ssj4Gogeta - Monday, March 30, 2009 - link
huh?ltcommanderdata - Monday, March 30, 2009 - link
I was wondering if you got any feeling whether Hyperthreading scaled better on Nehalem than Netburst? And if so, do you think this is due to improvements made to HT itself in Nehalem, just do to Nehalem 4+1 instruction decoders and more execution units or because software is better optimized for multithreading/hyperthreading now? Maybe I'm thinking mostly desktop, but HT had kind of a hit or miss reputation in Netburst, and it'd be interesting to see if it just came before it's time.TA152H - Monday, March 30, 2009 - link
Well, for one, the Nehalem is wider than the Pentium 4, so that's a big issue there. On the negative side (with respect to HT increase, but really a positive) you have better scheduling with Nehalem, in particular, memory disambiguation. The weaker the scheduler, the better the performance increase from HT, in general.I'd say it's both. Clearly, the width of Nehalem would help a lot more than the minor tweaks. Also, you have better memory bandwidth, and in particular, a large L1 cache. I have to believe it was fairly difficult for the Pentium 4 to keep feeding two threads with such a small L1 cache, and then you have the additional L2 latency vis-a-vis the Nehalem.
So, clearly the Nehalem is much better designed for it, and I think it's equally clear software has adjusted to the reality of more computers having multiple processors.
On top of this, these are server applications they are running, not mainstream desktop apps, which might show a different profile with regards to Hyper-threading improvements.
It would have to be a combination.
JohanAnandtech - Monday, March 30, 2009 - link
The L1-cache and the way that the Pentium 4 decoded was an important (maybe even the most important) factor in the mediocre SMT performance. Whenever the trace cache missed (and it was quite small, something of the equivalent of 16 KB), the Pentium 4 had only one real decoder. This means that you have to feed two threads with one decoder. In other words, whenever you get a miss in the trace cache, HT did more bad than good in the Pentium 4. That is clearly is not the case in Nehalem with excellent decoding capabilities and larger L1.And I fully agree with your comments, although I don't think mem disambiguation has a huge impact on the "usefullness" of SMT. After all, there are lots of reasons why the ample execution resources are not fully used: branches, L2-cache misses etc.
IntelUser2000 - Tuesday, March 31, 2009 - link
Not only that, Pentium 4 had the Replay feature to try to make up for having such a long pipeline stage architecture. When Replay went wrong, it would use resources that would be hindering the 2nd thread.Core uarch has no such weaknesses.
SilentSin - Monday, March 30, 2009 - link
Wow...that's just ridiculous how much improvement was made, gg Intel. Can't wait to see how the 8-core EX's do, if this launch is any indication that will change the server landscape overnight.However, one thing I would like to see compared, or slightly modified, is the power consumption figures. Instead of an average amount of power used at idle or load, how about a total consumption figure over the length of a fixed benchmark (ie- how much power was used while running SPECint). I think that would be a good metric to illustrate very plainly how much power is saved from the greater performance with a given load. I saw the chart in the power/performance improvement on the Bottom Line page but it's not quite as digestible as or as easy to compare as a straight kW per benchmark figure would be. Perhaps give it the same time range as the slowest competing part completes the benchmark in. This would give you the ability to make a conclusion like "In the same amount of time the Opteron 8384 used to complete this benchmark, the 5570 used x watts less, and spent x seconds in idle". Since servers are rarely at 100% load at all times it would be nice to see how much faster it is and how much power it is using once it does get something to chew on.
Anyway, as usual that was an extremely well done write up, covered mostly everything I wanted to see.
7Enigma - Wednesday, April 1, 2009 - link
I think that is a very good method for determining total power consumption. Obviously this doesn't show cpu power consumption, but more importantly the overall consumption for a given unit of work.Nice thinking.
JohanAnandtech - Wednesday, April 1, 2009 - link
I am trying to hard, but I do not see the difference with our power numbers. This is the average power consumption of one CPU during 10 minutes of DVD-store OLTP activity. As readers have the performance numbers, you can perfectly calculate performance/watt or per KWh. Per server would be even better (instead of per CPU) but our servers were too different.Or am I missing something?